6. Testing Assumptions#
Warning
I couldn’t complete this exploration in a timely manner, so I decided to assume it to be true and move forward. Not ideal, but necessary to finish in time.
As mentioned in this methodology section, …
6.1. Ecommerce dataset completeness#
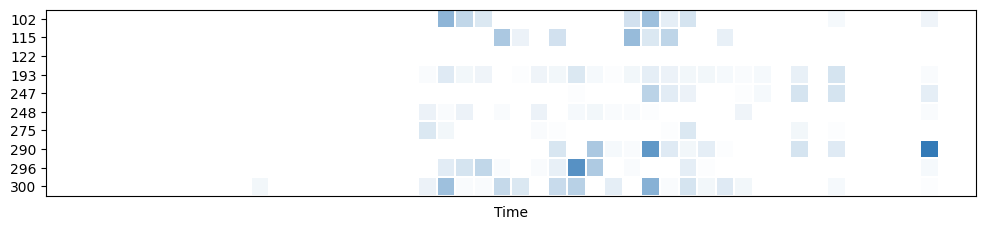
Before inspecting the data, my first assumption about our datasets is that Fintech and Ecommerce contain retailers’ time series data regarding their use of the platform. I expect to see at least columns equivalent to user_id, timestamp and invoice_value.
import pandas as pd
from ydata_profiling.visualisation.plot import timeseries_heatmap
df = pd.read_csv("../../data/Retailer_Transactions_Data.csv", header=0)
_ = timeseries_heatmap(
dataframe=df,
entity_column="MAIN_SYSTEM_ID",
sortby="CREATED_AT",
max_entities=10
)
import pandas as pd
from ydata_profiling.visualisation.plot import timeseries_heatmap
df = pd.read_csv("../../data/Ecommerce_orders_Data.csv", header=0)
_ = timeseries_heatmap(
dataframe=df,
entity_column="MAIN_SYSTEM_ID",
sortby="ORDER_CREATION_DATE",
max_entities=10
)
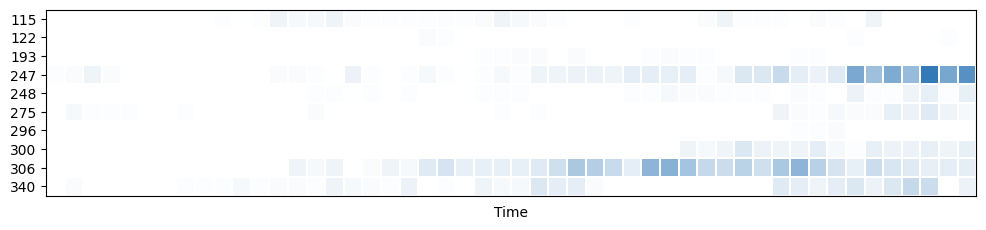
One interesting thought that came to my mind during the previous investigation is whether we can reconstruct SPENT from Ecommerce dataset. My assumption is that we can if the dataset is complete for every retailer present in Loans dataset.
Why is that an interesting question? Due to the nature of retailing in general, one can argue that inventory purchases follow a repeating pattern (e.g. purchased every 2 weeks) and also a seasonal one (e.g. cold beverages purchases go up in Summer). These patterns can be very helpful to predict when the retailer is likely to need a loan, but also how much more (or less) they are likely to purchase in the next cycle. Among many other use-cases, I believe this is crucial when it comes to priority retailers – retailers with whom we have a long-term relationship and are willing to reserve liquidity for them (even at a lower margin) to keep the relationship healthy.
Let’s test this assumption next. For every single loan, I will reconstruct SPENT from Ecommerce dataset and validate alignment between my aggregation and ground truth. If values mismatch, it means we have incomplete data in Ecommerce dataset. If the dataset is incomplete just for a portion of retailers in Loans datasets, then I must decide whether to only filter them in or to pivot to another approach.
# try:
# _ = ecommerce_df
# except NameError:
# ecommerce_df = (
# pd.read_csv("../../data/Ecommerce_orders_Data.csv", header=0)
# .assign(
# ORDER_CREATION_DATE=lambda df: pd.to_datetime(
# df["ORDER_CREATION_DATE"],
# infer_datetime_format=True
# )
# )
# )
# (
# ecommerce_df
# .query(
# "MAIN_SYSTEM_ID == 83079"
# + "and ORDER_CREATION_DATE >= @pd.to_datetime('2022-08-01')"
# + "and ORDER_CREATION_DATE < @pd.to_datetime('2022-10-01')"
# )
# .sort_values("ORDER_CREATION_DATE")
# )
from pyspark.sql import SparkSession, functions as F
import pandas as pd
spark = SparkSession.builder.getOrCreate()
try:
del loans_df
except:
pass
try:
_ = ecommerce_sdf
except NameError:
ecommerce_sdf = (
spark.read.csv("../../data/Ecommerce_orders_Data.csv", header=True)
.selectExpr(
"cast(ORDER_ID as long) as ORDER_ID",
"cast(MAIN_SYSTEM_ID as long) as MAIN_SYSTEM_ID",
"cast(ORDER_PRICE as float) as ORDER_PRICE",
"cast(DISCOUNT as float) as DISCOUNT",
"cast(ORDER_PRICE_AFTER_DISCOUNT as float) as ORDER_PRICE_AFTER_DISCOUNT",
"to_timestamp(ORDER_CREATION_DATE) as ORDER_CREATION_DATE",
)
)
try:
_ = loans_sdf
except NameError:
loans_sdf = spark.createDataFrame(pd.read_excel("../../data/Loans_Data.xlsx"))
23/05/08 12:56:44 WARN Utils: Your hostname, RyzenPc resolves to a loopback address: 127.0.1.1; using 192.168.31.225 instead (on interface wlp6s0)
23/05/08 12:56:44 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
:: loading settings :: url = jar:file:/home/ottok92/.spark/spark-3.3.1-bin-hadoop3/jars/ivy-2.5.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
23/05/08 12:56:45 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/05/08 12:56:45 WARN SparkConf: Note that spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL_DIRS in mesos/standalone/kubernetes and LOCAL_DIRS in YARN).
# del ecommerce_sdf
# try:
# _ = fintech_df
# except NameError:
# fintech_df = (
# pd.read_csv("../../data/Retailer_Transactions_Data.csv", header=0)
# .assign(
# CREATED_AT=lambda df: pd.to_datetime(
# df["CREATED_AT"],
# infer_datetime_format=True
# ),
# UPDATED_AT=lambda df: pd.to_datetime(
# df["UPDATED_AT"],
# infer_datetime_format=True
# )
# )
# )
# (
# fintech_df
# .query(
# "MAIN_SYSTEM_ID == 83079"
# + "and CREATED_AT >= @pd.to_datetime('2022-09-01')"
# # + "and CREATED_AT < @pd.to_datetime('2022-10-01')"
# )
# .sort_values("CREATED_AT")
# )
# # del fintech_df